


The ISO data processing is split into three parts, allowing the observer to choose himself from which data product he wants to start his own analysis of the data. A global overview of the processing is given in Figure 6.1.
The ISO processing is an automated process where the end products (Edited Raw Data, Standard Processed Data and Auto Analysis Results) are quality checked (see section 6.2. The following is a brief overview of the three steps in the processing. The algorithms used in the last two steps (Derive-SPD and Auto Analysis) are described in more detail in sections 6.3 and 6.4.
 |
The output of this process (Standard Processed Data or SPD) contains only scientific data, still in engineering units (i.e. not wavelength or flux calibrated), and in chronological order. Derive SPD processes a Target Dedicated Time (TDT) which can consist of more than one AOT. The individual data types (i.e. different AOTs or subsystems in the instrument) can be identified using LWS Compact Status History. This files is produced by TDF first scan. Derive SPD processes the raw detector read outs into photocurrent by fitting the raw data ramps. It also removes glitches due to particle impacts. Derive SPD also processes the measurements of the internal illuminators into a calibration file that is used by Auto Analysis.
A schematic overview of the Auto Analysis process is given in Figure 6.3.
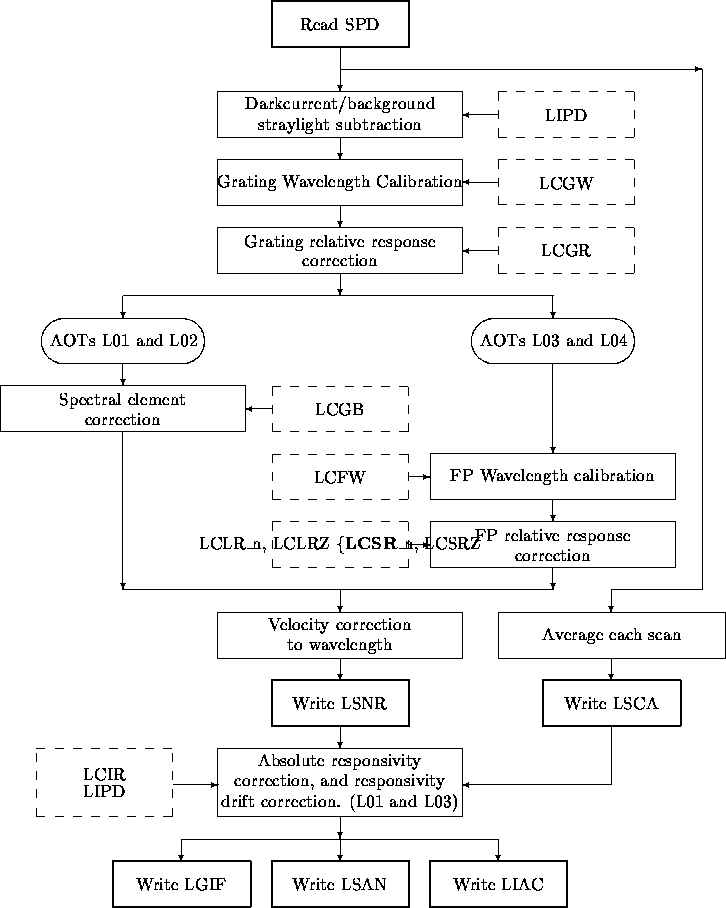 |
The calibrations performed by Auto Analysis also include a correction for the spectral bandwidth of the instrument and a correction for the effective aperture for a point source (internal to the responsivity correction, that was measured on a point source). Auto Analysis does not include:
The ISO dataproducts for those AOTs for which the OLP pipeline products have been declared scientifically validated are Quality Checked. This is to ensure that the observer does not get corrupted data. The quality check is performed at three levels.
The inputs to Derive SPD (SPL) are the LSTA file, science ERD files, the housekeeping ERD file (LWHK), the Executed observation history files (EOHI and EOHA), and various calibration files. The science ERD files consist of LGER for grating scan data, LLER for FPL scan data, LSER for FPS scan data, and LIER for illuminator flash data.
The outputs of SPL are the standard processed data file (LSPD), the illuminator processed data file (LIPD), and the glitch history file (LWGH). The LWGH file is for information only, and is not used during any further processing steps.
SPL is driven by the contents of the Compact status history file (CSH) for the selected observation. The LWS CSH file is named LSTA. The LSTA file identifies the regions of data taken in an observation with the grating, FP, or illuminator.
The first stage of SPL reads in all records from the currently open science ERD file that correspond to one ramp of data for all ten detectors. The LSTA file specifies which of the science ERD files the data is read from.
The start of a ramp is indicated by a detector readout which has its most significant bit set. The expected number of number of readouts per ramp is then read in. The expected number of readouts per ramp is obtained from the housekeeping ERD file (LWHK).
The ITK time key of each readout is checked as it is read in to identify any periods of missing data and to adjust the ramp contents appropriately.
After the ramp has been read in, some of the readouts have to be discarded for the following reasons:
The number of points discarded for the above reasons are written as keywords into the header of the LSPD file. See section 8.2.4 for details.
Before the raw detector readouts are converted into voltages, any invalid points are discarded. Any points which are outside the valid range for the analogue amplification chain are discarded. The valid range is specified in the LCAL calibration file. Note that this is NOT the same as the saturation of the detector, which is corrected later in the processing chain.
The number of readouts discarded for this reason are written as keywords into the header of the LSPD file. See section 8.2.4.
For each readout the raw detector readout (in digital units; DN) the
conversion to voltages is performed using the formula:
LCVC
(see section 8.2.6.3 for details).
The gain for the analogue amplification
chain is read from calibration file LCGA (see
section 8.2.6.4) using
the gain level (0-7) read from the detector word.
Finally the voltage as derived using formula 6.1 is divided by the
gain factor of the JF4 for the appropriate detector to reconstruct the
voltage at the input of the JF4's. The JF4 gain factor can be found in
calibration file LCJF (see section 8.2.6.5).
In previous versions of the pipeline saturated points had to be removed at this
stage. A saturated point is one where the voltage exceeds the threshold where
the model of the detector behaviour breaks down. This model has now been
replaced by the
![]() method, as described in section
4.2.
It is
therefore no longer necessary to throw away saturated points. However, it was
thought desirable to continue to flag any ramps which contain saturated points.
This stage therefore checks all of the points in the ramp and if one or more
points exceed the saturation threshold then the ramp is flagged as saturated in
the LSPD status word (see section 8.2.5.1).
The saturation thresholds can
be found in the
method, as described in section
4.2.
It is
therefore no longer necessary to throw away saturated points. However, it was
thought desirable to continue to flag any ramps which contain saturated points.
This stage therefore checks all of the points in the ramp and if one or more
points exceed the saturation threshold then the ramp is flagged as saturated in
the LSPD status word (see section 8.2.5.1).
The saturation thresholds can
be found in the LCDB calibration file (see section 8.2.6.6).
The number of saturated points and the number of ramps containing one or more saturated points are written into the header of the LSPD file (see section 8.2.4).
Glitches are caused by the effects of cosmic ray particles on the detectors. There is roughly one glitch per ten seconds per detector during the normal period of LWS operation. These energetic particles cause a sudden jump in the ramp voltage, due to a quantity of charge being dumped on the integrating amplifier. They also cause a change in the detector responsivity which affects the following ramps.
"Slow" glitches are glitches where the jump in voltage covers more than one readout value.
In addition to these "positive" glitches, "negative" glitches have also been found. These cause a sudden decrease in the ramp voltage, rather than an increase. They are thought to be due to hits on the FET. Negative glitches do not appear to affect the detector responsivity.
Before launch it was anticipated that "spikes" may also need to be located an removed. These are caused by spikes in the analogue amplification chain. They cause a single detector readout to have a much larger value than normal. Subsequent readouts are unaffected and there is no effect on subsequent ramps. However, no real spikes have yet been seen in the data since launch. The spike removal has been switched off as all of the "spikes" detected were actually caused by the effects of glitches. A modified spike detection is still operational, but it would be more accurate to describe it as an "anomaly" detector, rather than a spike detector. This anomaly could be cause by a real spike, but it is more likely to be caused by undetected glitches, or the effects of glitches which have been detected. These points will be examined to help improve the detection of real glitches. If any real spikes are found then it may be necessary for a modified spike removal stage to be added.
Statistics related to glitches and spikes are written into the header of the LSPD file. See section 8.2.4 for details.
The following list describes how glitches and "spikes" (see introduction) are detected. Note that glitch detection is only performed on the section of ramp after the discarding of data due to the reset pulse etc. Any glitches which occur in this discarded section of ramp are not currently detected. This problem may be addressed in future versions of SPL.
LCD1 calibration file.
If a glitch is detected by this step then the next three points are not checked for glitches. This is because it has been found that the effects of a glitch often caused a second, false glitch, to be detected shortly afterwards. No "spike" detection is done for the remainder of a ramp following a glitch. This is because it has been found that the effects of glitches caused lots of false "spikes" to be detected.
The height of a spike is estimated by subtracting the voltage of the previous point from the voltage of the spiked point. The expected voltage increment due to the ramp slope is then subtracted from this value.
There is a special case for the first point in the ramp, since there will be no previous point. In this case the spike height is obtained by subtracting the voltage of the point following the spike from the voltage of the spiked point. The expected voltage increment due to the ramp slope is then ADDED to this height. The height of a glitch is estimated by finding the difference between the point at the glitch location and a point a few places ahead (3, at the time of writing). This is to cope with slow glitches, or glitches that have noise. If the second point is beyond the end of the ramp then the last point in the ramp is used.
The expected nominal ramp increment over the time period between these two points is calculated and subtracted from the glitch height.
For spikes the fractional height with respect to the height
of the ramp is calculated. The height of the ramp is simply the
voltage of the last point in the ramp minus the voltage of the first
point in the ramp. Only those spikes with fractional heights above the
threshold specified in the LCD1 calibration file are accepted.
For glitches the same procedure is performed, except that the
glitch height is also subtracted from the height of the ramp.
This should give the height of the ramp if no glitch has occurred.
There is a separate threshold level specified in the LCD1 file for
the fractional heights of glitches.
Note that these calculations have assumed that there is only one spike or glitch in the ramp.
Note that the `location' of a glitch is understood to mean the point before the outlying point(s):
*-*-*
/
*-*
^
Glitch location
Using test data it has been found that `slow' glitches are often detected only on the second point of the glitch:
*-*
/
* <--------- Glitch detected here
/
*-*
In order to cope with this, the point at the glitch location is always discarded. For normal `fast' glitches this will mean that one possibly good point is thrown away.
This section details the patterns which identify spikes and glitches. The following conventions are used:
Positive glitch at point n in ramp
==================================
ramp point n-1 n ramp point n-1 n
OUT1 * 1 OR OUT1 * 1
OUT2 1 * OUT2 * 1
The second of these checks tends to catch the `slow' glitches, which cover more than one point.
For the first point in the ramp only the second of these test for positive glitches is done, as there are no previous points to check.
Negative glitch at point n in ramp
==================================
ramp point n-1 n ramp point n-1 n
OUT1 * -1 OR OUT1 * -1
OUT2 -1 * OUT2 * -1
No check is done for negative glitches at the first point in the ramp. Negative glitches at the first point in the ramp will be recorded as a positive "spike". It remains to be checked whether this is the correct thing to do.
If the number of points in a ramp is NPOINTS, then these checks for glitches can only be done for n=1 to NPOINTS-2, as there are only NPOINTS-2 values for the second differential. This means that if the last point of a ramp is an outlier, then it will be reported as a spike, rather than a glitch. There is no way of telling the difference between a spike at the last point and a glitch.
Positive spike at point n in ramp
=================================
ramp point n-1 n
OUT1 1 -1
OUT2 * *
There is a special case for the first point in the ramp, as there is no previous point to check. In this case if OUT1 is -1 (ie. a negative outlier) then this is regarded as a positive spike at this point.
Negative spike at point n in ramp
=================================
ramp point n-1 n
OUT1 -1 1
OUT2 * *
It is not possible to distinguish between a negative spike at the first point in the ramp and a positive glitch at this point. Therefore, no check for negative spikes is performed for the first point. A negative spike at the first point will be reported as a positive glitch.
The glitches identified using the method described above are now removed. The way in which this is done is controlled by the values in the LCD1 calibration file. Note that the removal of glitched data is done after all glitches have been identified. This means that glitches which occur during ramps discarded because of glitches in previous ramps are still identified. The following description is based on the current contents of the LCD1 calibration file (version 8). If the LCD1 file is updated then this description may no longer be valid. Check the LCD1 file if you are in any doubt.
For positive glitches all of the ramp following the glitch is discarded, plus the two subsequent ramps. The section of ramp before the glitch occurred is still used, provided that it has at least the minimum number of points required for slope fitting (this value is specified in an include file and is currently set to 10).
Negative glitches are handled in the same way as positive glitches, except that no ramps are discarded following the glitched ramp.
The deglitching performed during illuminator flashes is slightly different from the above description. See section 6.3.7 for details.
The LSPD file also contains the "undeglitched" data, ie. the results when there is no discarding of data due to glitches.
Information about each glitch detected, including the time, the glitch height and the detector number, is written into the glitch history file (LWGH). This file is for informational purposes only. It is not used as an input for any further processing steps.
The theory behind the conversion of ramps slopes to photocurrents is given in
section A. Starting with OLP version 7 the `
![]() ' method has been used. For each ramp of each detector, the points which have
not been discarded by previous stages are processed as follows:
' method has been used. For each ramp of each detector, the points which have
not been discarded by previous stages are processed as follows:
| (6.2) |
| (6.3) |
Where:
| (6.4) |
| (6.5) |
In addition to the detector photocurrent, the `RMS of the detector ramp fit' is also calculated. This gives a measure of how well the points in the ramp were fitted by the second order polynomial. In previous versions of SPL this value was called the `uncertainty' in the photocurrent. However, this was an inaccurate description and this value should not be used as an uncertainty. The RMS of the detector ramp fit is calculated as follows:
![\begin{displaymath}RMS = C_{JF4} \sqrt{\frac{\sum [V(t_{i})-F(t_{i})]^2}{N_{points}}}
\end{displaymath}](img30.gif) |
(6.6) |
The calculated photocurrent and RMS of the fit are now written into the LSPD file, together with a time key, grating and FP positions and other information. The time key assigned is the ITK time value of the start of the ramp.
If for any reason the photocurrent has not been calculated for this ramp then both the photocurrent and uncertainty will be set to zero. The most common reason for this is a glitch which has caused all of the data to be discarded. The status word should also indicated that this point is not valid (see section 8.2.5).
For calibration purposes each observation includes two or more periods when the internal illuminators are used. The data from these `illuminator flashes' are identified by SPL, processed, and the results written into an LIPD file. This file is then used as an input to AAL.
Each illuminator flash consists of a dark current measurement, followed by a sequence in which different illuminators are flashed at one or more different levels, followed by another dark current measurement. For grating scans, at least two of the illuminator flashes are `closed' flashes, where the FP is moved into the beam. This removes the source from the beam and means that the dark current measurement during the illuminator flash is a measure of the dark current/straylight. For FP scans all flashes will be `closed' flashes.
The processing of the ramps in illuminator flashes is identical to the processing of ramps of science data, as previously described. The only difference is in the handling of glitches. The LCD1 file contains a separate set of parameters which control the handling of glitches during illuminator flashes. The current setting of these parameters (version 8 of the LCD1 file) means that the whole of a glitched ramp will be discarded, but not subsequent ramps are discarded.
After each ramp in the illuminator flash has been processed it is written into the LIPD file. The LIPD file is analogous to the LSPD file, except that it contains data from illuminator flashes rather than science data. The LIPD file contains the photocurrents for each ramp for each detector, plus auxiliary information such as the value of the illuminator commanded status word and the illuminator current.
Each observation contains at least two `closed' illuminator flashes. During these illuminator flashes the wheel is set to an opaque position, removing the flux contributions due to the source. This is achieved by placing one of the FPs in the beam with the etalons mis-aligned. For grating observations, at least the first and last flashes in the observation will be closed flashes. For FP observations, all flashes are closed flashes since the FP is already in the beam and the etalons are mis-aligned before the illuminator flash is taken.
The background measurements during these closed illuminator flashes are a measure of the `dark signal' at the time they were taken. (The `dark signal' is the sum of the dark current and straylight). There is a separate background value for each detector. The values for the background measurements for the closed illuminator flashes are calculated using the information in the LIPD file. See section 6.4.9.2 for details of how the background values are calculated. The backgrounds for each illuminator flash in the observation are written into the LIAC file. The closed illuminator flashes in the LIAC file are identified by the wheel absolute position field being set to either 0 (FPS) or 2 (FPL).
Between each pair of closed illuminator flashes in the observation a single darkcurrent/straylight value is calculated for each detector. This is done by taking the mean of the two values from the surrounding flashes. The uncertainty in this value is given by the maximum of the two uncertainties from the surrounding flashes.
The dark current/straylight value is then subtracted from all of the detector photocurrent values between the pair of illuminator flashes. The uncertainty in the photocurrent is calculated by adding the uncertainties in the dark current/straylight and input photocurrent in quadrature. The dark current/straylight value suntracted from each scan is written into the scan summary file (LSCA). See section 8.2.7.4 for details of the LSCA file.
The grating mechanism positions are converted into wavelengths by this stage. The input to this stage is the grating measured positions (LVDT readouts) and the calibration information in the LCGW file. See section 8.2.9 for a description of the LCGW file. The conversion is performed by means of an algorithm. The coefficients required for the algorithm are stored in the LCGW file.
It has been found that the relationship between LVDT and wavelength changed over time. The LCGW file therefore contains different coefficients for different time periods.
The wavelength conversion is performed in two steps. The first step is to
calculate the input beam angle to the grating,
![]() ,
for all ten
detectors. This is calculated using the following formula:
,
for all ten
detectors. This is calculated using the following formula:
| (6.7) |
Where:
The input beam angle is then converted into wavelength for each detector by applying the grating equation and the geometry applicable to that detector. This is done using the following formula:
| (6.8) |
Where:
The efficiency of the LWS as a spectrometer varies with wavelength, mainly due to the bandpass filtering incorporated into each detector unit and the spectral response of the detector itself.
The Grating Relative Responsivity Wavelength Calibration File, LCGR (see section 8.2.9), contains a spectrum
of the relative response of the instrument in grating mode. The wavelength for
each point in the spectrum is looked up in this table and the corresponding
responsivity value read. If no exact wavelength match is found within the table
then a responsivity value is calculated by linear between surrounding
wavelength entries. The responsivity corrected flux then is calculated by
dividing the flux by the responsivity value.
For version 7 of OLP the wavelength range in the LCGR file has been
extended compared to the version 6 file. This is to allow for wavelength
identification of features on overlapping detectors. The photometric
calibration at the edges of the range is very poor, due to poor Signal to
noise ratio and detector memory effects. This region should therefore not be
used for anything except wavelength identification of features. Data in this
region can be identified by means of the `grating spectral responsivity
warning' flag in the LSAN status word (see section 8.2.8).
When this warning
flag is set this indicates that the data point has poor calibration and should
not be used for anything other than wavelength identification. The wavelength
ranges for which the LCGR calibration is nominal are also specified by keywords
in the LCGR header (see section 8.2.9.4)
The correction is currently only done for grating scans.
The LCGB calibration file contains the spectral element size and uncertainty
for each of the ten detectors. Auto Analysis simply divides the flux for each
detector by the appropriate spectral element size to perform the correction.
The new flux uncertainty is calculated using the standard error formula.
The values of the spectral element sizes and uncertainties are written as
keywords into the header of the LSAN file. Keywords LCGBddd contain the
spectral element size for detector ddd (ddd='SW1'...'LW5'), while keywords
LCGBUddd contain the corresponding uncertainties.
The wavelength calibration of a FP scan is done using a parametrised algorithm for the FP wavelength calibration. The wavelength calibration for FP spectra is done as follows:
| (6.9) |
LCFW (see
section 8.2.9).
| (6.10) |
| (6.11) |
This stage adjusts the flux of each point by the responsivity value at the current FP and grating position. The responsivity values are stored in the LCLRZn, LCSRZn, LCLR_n and LCSR_n files. The LCLR_n files contain the relative responsivity values for a range of relative FP positions for detector n (n=0-9) for FPL. The LCSR_n file contains the same information for FPS. The LCLRZn (where n is 1 or 2) files contain the absolute FP zero position in the LCLR_n file for a range of grating positions for FPL. The LCLRZ1 file is for observations done before revolution 346 and the LVLRZ2 file is for observations done after revolution 346. This is to reflect the diffenent grating wavelength calibrations used for these two periods. The LCSRZn files contain the same information for FPS. This allows the relative FP positions in the LCSR_n or LCLR_n files to be converted into absolute positions. Using these files it is possible to determine the responsivity value for each possible FP and grating position combination.
The correction applied by this stage simply consists of dividing the flux by the responsivity value.
The grating spectral responsivity calibration, described in section 6.4.3, is also applied to FP data.
The wavelengths calculated in the previous stages are corrected for the velocity of the spacecraft and earth towards the target. The header of the LSPD file contains keywords which specify this velocity at three points during the observation. These keywords are written by a subroutine written by ESA which is external to the LWS pipeline. See section 6.3 of the ISO Data Products Document (entitled `General FITS keywords for SPD') for details of these keywords.
The velocity at each mechanism position in a scan is calculated by
interpolating in time between the three given values. A second order curve fit
is used for the interpolation. Once calculated, the coefficients of this fit
are written into the LSAN header as the keywords LVCOEFFn (n=0-2).
The wavelength at each mechanism position is then corrected using the following formula:
| (6.12) |
Where:
At this stage the results are written into the first product file produced by Auto-Analysis, named LSNR. This file is identical in structure to the final LSAN file, apart from a few minor differences. This file is provided to give observers access to the data before the absolute responsivity correction and responsivity drift corrections are applied. In a few cases these corrections do not work sucessfully. The LSNR file provides an alternative product file for those cases.
The photoconducting detectors in the LWS drift in responsivity owing to the impact of ambient ionising radiation. This drift in responsivity must be corrected for to allow the co-adding of individual scans without introducing extraneous noise. This is referred to as the responsivity drift correction. The spectra must also be corrected to an absolute flux scale. This is referred to as the absolute responsivity correction. The following sections describe how these corrections are performed.
From version 7 of the pipeline onwards the responsivity drift correction will only be performed for AOTs L01 and L03. This is because the correction did not work very sucessfully for L02 and L04 AOTs. The keyword LORELDN in the LSAN header indicates if the responsivity drift correction has been performed or not.
Before these corrections are applied, the data must be divided into `groups'. Each group will have a separate responsivity drift correction and absolute responsivity correction calculated and applied. The LGIF, group information file, contains one record for each group. The LGIF file identifies the start and end ITK of each group and also records information which is constant over the group. This includes the absolute responsivity and responsivity drift correction information for the group.
The grouping of data depends upon the AOT type. The easiest way of describing the grouping is to define the condition for the current group to end and a new group to start. A new group starts when:
Note that there is a special case for L02 photometric observations. In this case all data between each pair of closed illuminator flashes are grouped together.
For each group identified, a single reference time is calculated. This is point at which the absolute responsivity correction will be calculate for the group. It is also the point where the responsivity drift correction will be normalised.
The reference time is simply half way between the ITK of the start and end of the group. This reference time is written into the LGIF file.
The first stage of the absolute responsivity correction is to process each illuminator flash in the observation. The aim is to find for each flash the ratio between the detector photocurrents from the flash and the reference photocurrents stored in the LCIR calibration file.
Only the `closed' illuminator flashes are used for the absolute responsivity correction. However, all illuminator flashes are first processed using the same method. The results of processing each flash are written into the LIAC file. This file contains one record for each flash in the observation.
The data for all illuminator flashes in each observation are read from the LIPD data file produced by SPL. This file contains the detector photocurrents for each ramp in each flash, plus the illuminator commanded status word and other information.
The first stage of processing an illuminator flash is to determine the background photocurrent for each detector. These backgrounds will also be used in the dark current/straylight subtraction stage (see section 6.4.1). The background value for each detector for each flash is written into the LIAC file.
The method for determining the background is as follows:
The uncertainty to be associated with
this value is given by
![]() for the set of averaged
photo-currents. If there are less than three photo-current
values then the maximum of the individual photo-current uncertainties
is used.
for the set of averaged
photo-currents. If there are less than three photo-current
values then the maximum of the individual photo-current uncertainties
is used.
The purpose of median clipping is to remove any outlying values from a set of measurements of the same value.
There must be at least five values in order for median clipping to be performed.
The method for median clipping is as follows:
For each illuminator flash a single absolute responsivity ratio is calculated for each detector. This is done by ratioing the photocurrents in the illuminator flash against reference flash data in the LCIR calibration file. The final ratio for each detector is written into the LIAC file.
The method for calculating the ratio for each detector is as follows:
Skip any photocurrent values which are set to zero in the LIPD file or the LCIR file. Skip any values for which the status word in the LCIR file indicates that it should be ignored.
If while doing this, data is found to be missing from the LIPD file then jump to the start of the next illuminator level in the LIPD and LCIR files. Missing data are detected by a mismatch between the illuminator commanded status value in the LIPD and LCIR records. The warning message `LIMM' is issued each time this occurs. Data may be missing from the LIPD file because of telemetry dropouts or frame checksum errors. The LCIR file should not have any missing data.
Once all illuminator flashes have been processed the absolute responsivity can be performed.
For each group identified in the LGIF file the absolute responsivity ratio for each detector at the reference ITK time is calculated. This is done using the data from the two closed illuminator flashes which surround the reference ITK. For each detector the absolute responsivity correction factor is calculated by doing a linear interpolation in time between the values at the two surrounding closed illuminator flashes. The uncertainty in this value is calculated as the highest of the uncertainties for the two surrounding values. The value of the correction factor and its uncertainty are written into the LGIF file.
The absolute responsivity correction is then performed on all of the data within the group by simply dividing each flux value in the LSNR file by the absolute responsivity correction factor.
The responsivity drift correction corrects for the `drift' in responsivity during an observation. The drift is obtained from the information in the LSCA scan summary file. The responsivity drift is calculated separately for each group of data identified in the LGIF file.
The responsivity drift correction is only performed for AOTs L01 and L03. No drift correction is performed for AOTs L02 and L04.
The LSCA scan summary file contains summary information for every scan in the observation. This includes a value which represents the signal level over the whole scan. This is calculated by finding the average signal per point in the scan. The signal values used are the values from the LSPD file, before any further processing. Any values which are marked as `invalid' in the LSAN status word are not included in this average.
For each scan a reference ITK time is also calculated. This is simply the mid point between the ITK times of the start and end of the scan.
Note that for L02 photometric observations no LSCA file is produced. This is because no responsivity drift correction is needed on this data. Also, since AAL regards each point in a photometric observation as a single scan, the LSCA file would be very large and would contain the same information as the LSAN file.
For each group of data identified in the LGIF file a separate drift slope is calculated for each detector. The method is as follows:
Short scans are identified by comparing the total number of points (ramps) in each scan with the number of points in the first scan in the group. The first scan of a group is assumed to be a full scan. If the number of points in a scan is below half of the number in a full scan then it is classified as a short scan and discarded.
Note that the total number of ramps in a scan can also vary because of missing frames of telemetry data.
Note that in certain cases there may be insufficient valid data to determine a drift slope. This can happen for the inactive detectors in FP observations. The flag LGIFRSTA in the LGIF file indicates when this happens. In this case no responsivity drift correction is performed.
Once the drift slopes have been calculated for each detector in each group the responsivity drift correction can be applied.
For each group identified in the LGIF file the corresponding flux data in the LSNR file are corrected. The method for correction is as follows:
The LSAN file contains the field LSANFLXU which contains the `fractional systematic flux error due to calibration'. This is the fractional uncertainty due to the grating and FP spectral responsivity calibrations and the absolute responsivity correction. The LSNR contains the field LSNRFLXU, which contains the same uncertainty value, but without the component due to the absolute responsivity correction. These values on their own do not give you the uncertainty on the flux, but they do give you some of the information needed in order to calculate this uncertainty. The exact definition of the contents of these fields are given below:
For grating AOTs (L01 and L02) the LSNRFLXU field in the LSNR file is defined as follows:
| (6.13) |
Where RGR is the grating responsivity correction and
![]() is
its associated uncertainty. Both of these values are obtained from the LCGR
calibration file.
is
its associated uncertainty. Both of these values are obtained from the LCGR
calibration file.
For FP AOTs (L03 and L04) the LSNRFLXU field in the LSNR file contains an additional term as show below:
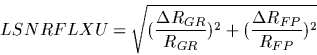 |
(6.14) |
Where RFP is the FP
responsivity correction and
![]() is its associated uncertainty.
Both of these values are obtained from the set of LCLR_n and LCSR_n
calibration files.
is its associated uncertainty.
Both of these values are obtained from the set of LCLR_n and LCSR_n
calibration files.
For grating AOTs (L01 and L02) the LSANFLXU field in the LSAN file is defined as follows:
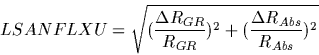 |
(6.15) |
Where RAbs is the absolute responsivity correction and
![]() is its associated uncertainty. The values for RAbs and
is its associated uncertainty. The values for RAbs and
![]() are written into the LGIF file (see section 8.2.7.5).
are written into the LGIF file (see section 8.2.7.5).
For FP AOTs (L03 and L04) the LSANFLXU field in the LSAN file is defined as follows:
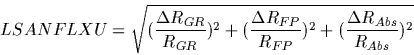 |
(6.16) |
